

AI face generation has rapidly evolved, leveraging advanced machine learning and neural network techniques. This document delves into the primary methods used to generate AI faces, focusing on Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and other relevant techniques. Understanding these methods is crucial for recognizing their capabilities, limitations, and broader implications.
1. Generative Adversarial Networks (GANs)
A. Principles:
Generative Adversarial Networks (GANs) consist of two neural networks: a generator and a discriminator. These networks are trained simultaneously through adversarial processes:
Generator: Creates fake images from random noise.
Discriminator: Evaluates whether an image is real or fake.
Adversarial Process: The generator improves by trying to fool the discriminator, while the discriminator enhances its ability to distinguish real from fake images.
B. Strengths:
High Realism: Capable of producing highly realistic images, often indistinguishable from real photographs.
Versatility: Applicable to various types of image generation beyond faces, including landscapes, objects, and textures.
C. Limitations:
Training Instability: GANs can be challenging to train due to issues like mode collapse where the generator produces limited diversity in outputs.
Resource Intensive: Requires substantial computational power and large datasets to achieve high-quality results.
D. Practical Applications:
Entertainment and Media: Used in video games, movies, and virtual reality to create realistic characters and environments.
Synthetic Data Generation: Generates training data for machine learning models, particularly in scenarios where real data is scarce or sensitive.
E. Implications:
Deep fakes: Potential misuse in creating misleading videos and images, raising ethical and security concerns.
Privacy: Challenges in ensuring individuals’ likenesses are not misused without consent.
F. Implementation:
Architecture: Typically involves deep convolutional neural networks (CNNs).
Training Process:
Step 1: The generator creates images from random noise.
Step 2: The discriminator evaluates the images against real images.
Step 3: Both networks are updated based on the discriminator’s feedback, with the generator trying to improve its ability to create convincing images.
Output Characteristics: High-resolution, realistic images with diverse variations.
G. Notable Models:
Style GAN: Introduces a novel architecture separating high-level attributes from stochastic variation, leading to high-quality, customizable face generation.
2. Variational Autoencoders (VAEs)
A. Principles:
Variational Autoencoders (VAEs) are generative models that learn the underlying distribution of data to generate new, similar data points.
Encoder: Maps input data to a latent space, representing compressed data.
Decoder: Reconstructs data from the latent space.
Regularization: Introduces a regularization term in the loss function to ensure a smooth and continuous latent space.
B. Strengths:
Smooth Interpolations: VAEs produce smooth transitions between different data points in the latent space.
Latent Space Representation: Provides a meaningful and structured latent space, useful for various generative tasks.
C. Limitations:
Lower Detail: Often produces images with less detail and sharpness compared to GANs.
Blurriness: Generated images can appear blurry, especially for complex datasets.
D. Practical Applications:
Image Reconstruction: Used in applications requiring the reconstruction of images from compressed representations.
Anomaly Detection: Identifies anomalies by comparing reconstructed images to original inputs.
E. Implications:
Quality of Generated Content: Suitable for applications where exact realism is less critical, such as data augmentation and preliminary visualizations.
f. Implementation:
Architecture: Comprises an encoder and a decoder, often using convolutional layers.
Training Process:
Step 1: The encoder compresses the input data into a latent representation.
Step 2: The decoder reconstructs the data from the latent space.
Step 3 : The loss function combines reconstruction error and a regularization term to ensure smooth latent space.
Output Characteristics: Images that capture the general structure of the input data but may lack fine details.
3. Deep Learning-Based Approaches
3.1 Deep Fakes:
Deep fakes use deep learning models, particularly auto encoders, to create realistic face swaps and manipulated videos.
Auto encoders: Consist of an encoder that compresses the input image and a decoder that reconstructs the image from the compressed representation.
Training: Typically involves training on paired data of the source and target faces to learn the mapping between them.
A. Strengths:
Realism: Capable of producing highly realistic face swaps and videos.
Accessibility: Various open-source tools make deep fake creation accessible to the public.
B. Limitations:
Ethical Concerns: High potential for misuse in creating misleading content.
Detection: Growing sophistication makes it increasingly difficult to detect deep fakes.
3.2. DALL-E:
DALL-E, developed by Open AI, generates images from textual descriptions, demonstrating the capability to create coherent images from text prompts.
A. Strengths:
Diversity: Can generate a wide range of images from diverse textual inputs.
Creativity: Enables the creation of novel and imaginative visuals.
B. Limitations:
Quality Control: Ensuring the generated images meet specific quality standards can be challenging.
Computational Resources: Requires significant computational power for training and inference.
C. Implementation:
Architecture: Utilizes transformers and other deep learning architectures for text-to-image generation.
Training Process:
Step 1: The model is trained on large datasets of images and corresponding textual descriptions.
Step 2: It learns to generate images that match the provided text prompts.
Output Characteristics: Diverse images that align with the input text, showcasing creativity and coherence.
Conclusion.
AI face generation technologies, particularly GANs and VAEs, have revolutionized the creation of realistic synthetic faces. These advancements offer numerous benefits across various industries, from entertainment to data augmentation. However, they also pose significant ethical and security challenges. Understanding these methods is essential for developing effective detection mechanisms and addressing the broader implications of AI-generated content.
Code to View AI-Generated images and Real Images
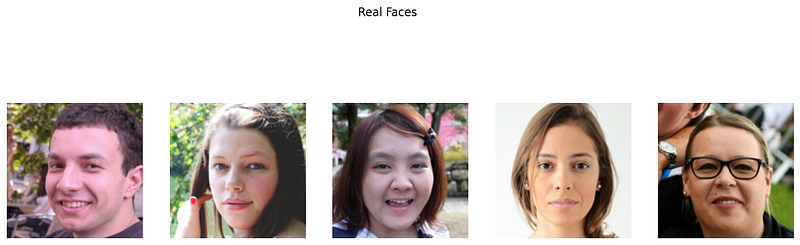
Output:

👉The Next Step
Read the previous episode-1 or keep an eye out for the next episode-3, where we’ll dive deeper into Existing Orientation Detection Techniques. More excitement awaits as we push the boundaries of digital security and trust.!
Related articles

Real Versus AI
With the increasing prevalence of AI- generated faces, detecting such synthetic content has become crucial for maintaining digital integrity and security. Various techniques and tools have been …
Lets us help you bring your dream to life!
We are here to understand your needs and provide solutions across various areas of technology and business. Join us on this transformative journey as we transform the future into a tangible reality.